
Last Updated on 08/28/2024 by rromruns
AMD โชว์ภาพดีไซน์ภายในของสถาปัตยกรรมชิปใหม่ Zen 5 ที่เน้นเรื่องประสิทธิภาพความแรงมาแบบเน้น ๆ
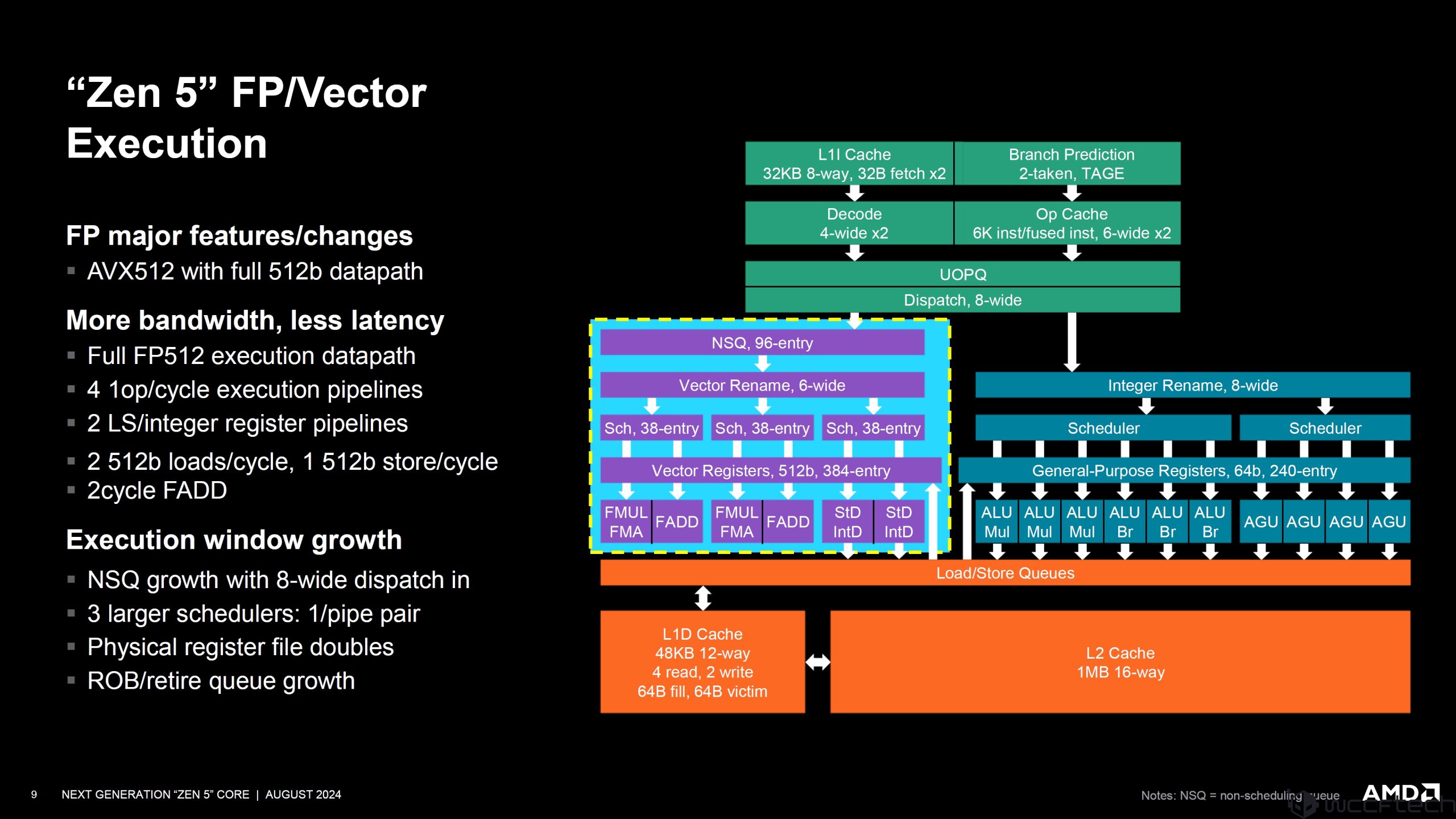
เพิ่มความแรง IPC มามากขึ้นกว่าเดิมอีก 16% เลยทีเดียว พร้อมรองรับชุดคำสั่ง AVX-512 และ FP-512 ให้แบนด์วิดท์มากกว่าเดิมและลดระยะเวลาความหน่วงที่ 4 1op/cycle execution pipelines, 2 LS/integer register pipelines, 2 512b loads/cycle, 1 512b store/cycle, และ 2 cycle FADDs ผลิตด้วยเทคโนโลยี 4nm/3nm

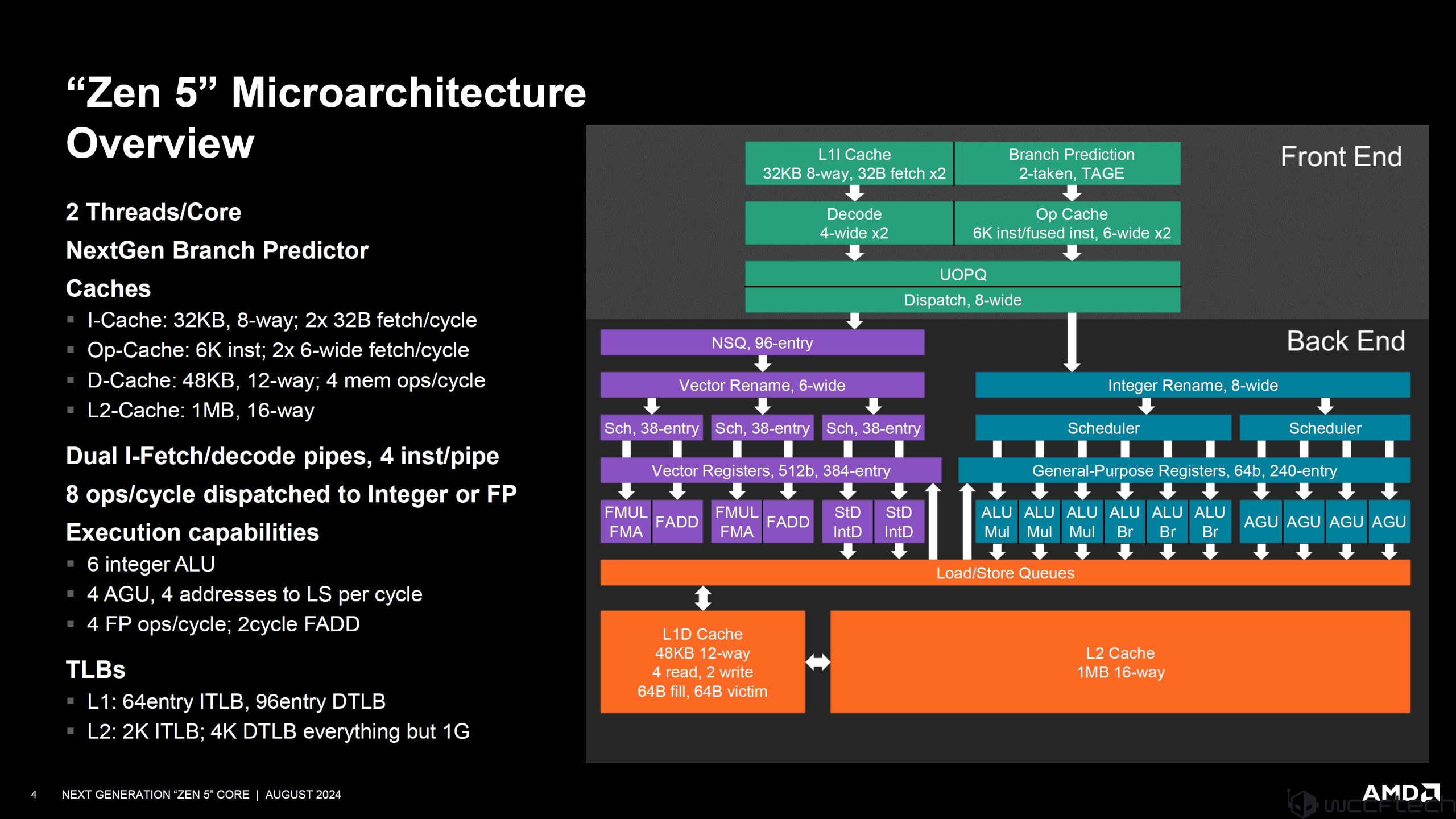
โอเวอร์วิว AMD Zen 5:
2 Threads/Core
NextGen Branch Predictor
Caches:
- I-Cache: 32KB, 8-way; 2x32B fetch/cycle
- Op-cache: 6K inst; 2x 6-wide fetch/cycle
- D-Cache: 48KB, 12-way; 4mem ops/cycle
- L2-Cache: 1MB, 16-way
Dual I-Fetch/decode pipes, 4 inst/pipe
8 ops/cycle dispatched to integer or FP
Execution capabilities:
- 6 Integer ALU
- 4 AGU, 4 addresses to LS per cycle
- 4 FP ops/cycle; 2cycle FADD
TLBs:
- L1: 64 entry ITLB, 96entry DTLB
- L2: 2K ITLBl 4K DTLB everything but 1G

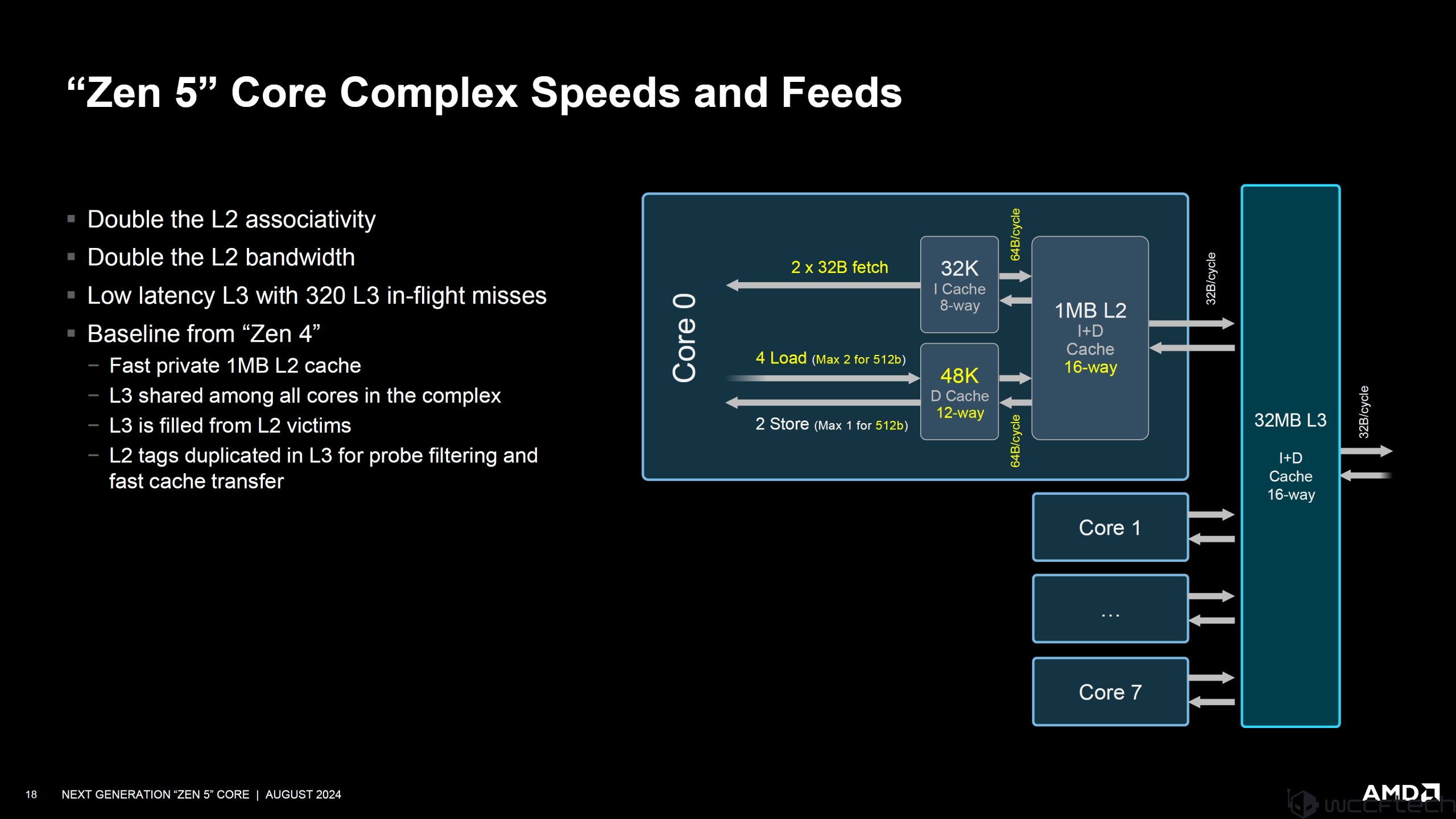
มีการปรับสมดุลของชุดคำสั่งประมวล 1T/NT มาอย่างดี สามารถทำงานแบบคู่ขนานได้ดีขึ้นกว่าเดิม ด้านแคชมีการอัปเกรดแบนด์วิดท์อินเทอร์เฟส L2/core มากกว่าเดิม 2 เท่า ด้วย 64B/clk ให้กับ L1 และ L1D
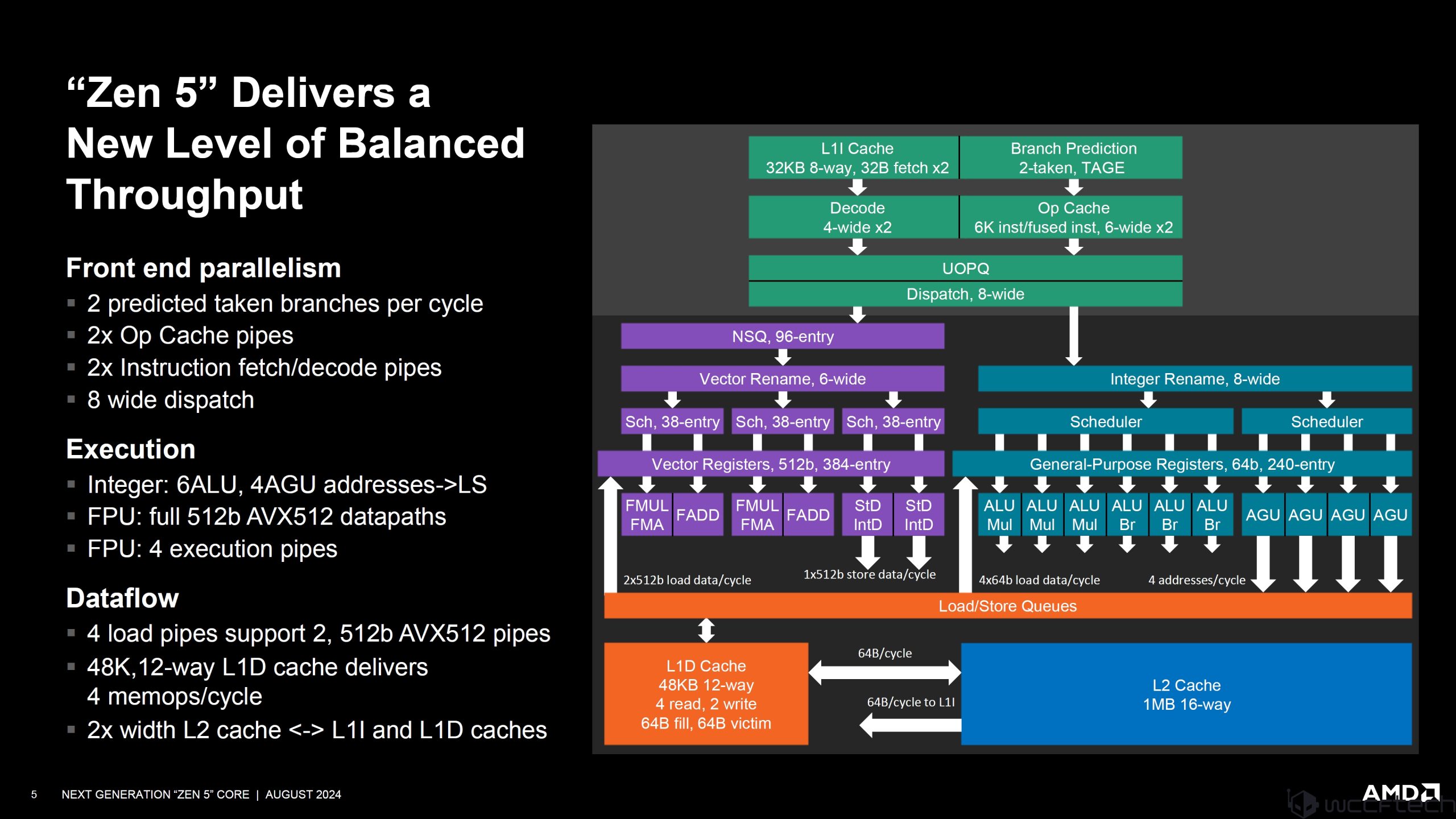
Front End parallelism:
- 2 predicted token branches per cycle
- 2x Op cache pipes
- 2x instruction fetch/decode pipes
- 8 wide dispatch
Execution:
- Integer: 6ALU, 4AGU addresses->LS
- FPU: full 512b AVX512 datapaths
- FPU: 4 execution pipes
Dataflow:
- 4 load pipes support 2, 512b AVX512 pipes
- 48K, 12-way L1D cache delivers 4 memops/cycle
- 2x width L2 cache <-> L1I and L1D caches

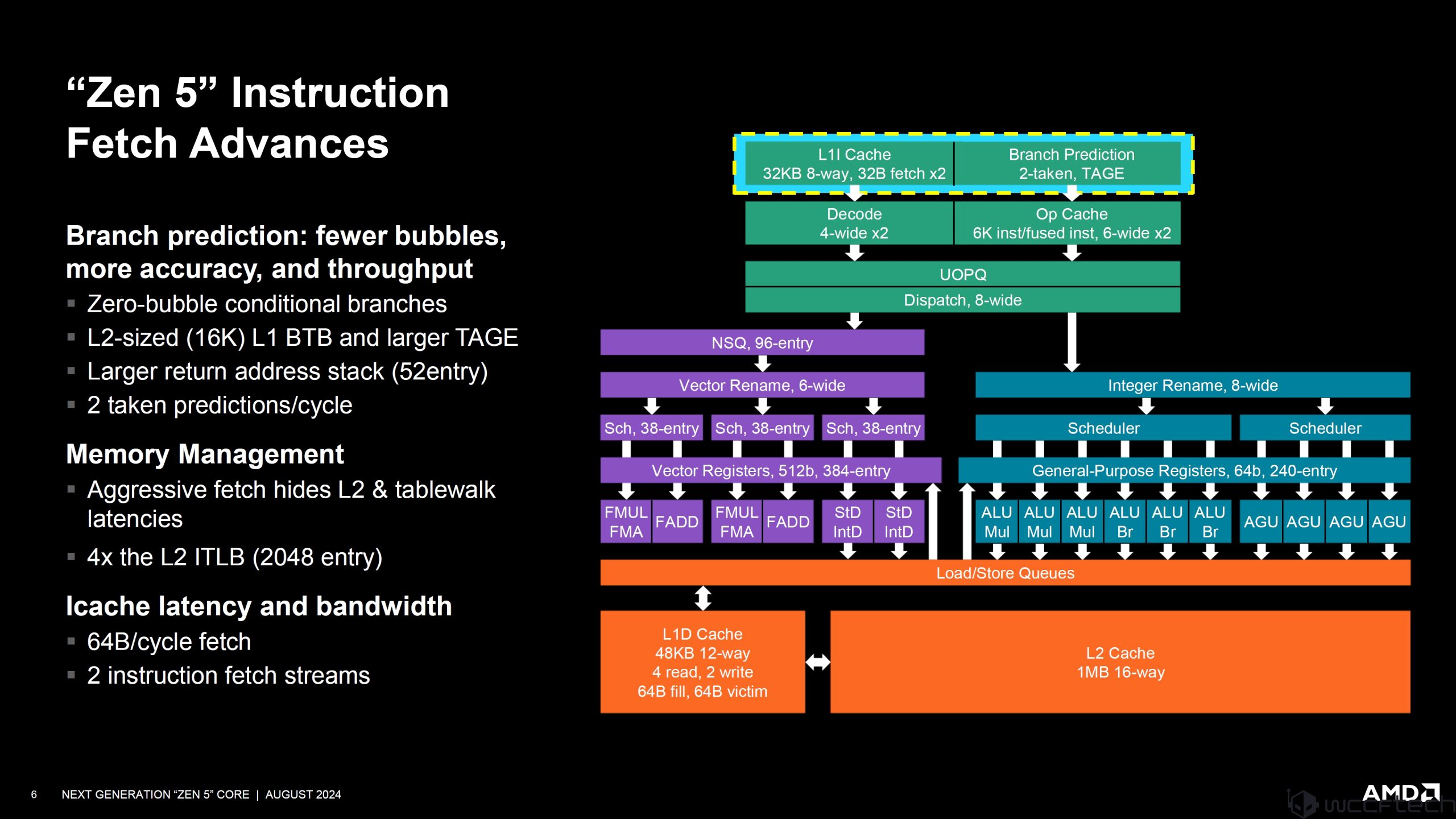
และด้าน Fetch Advances ก็ให้ปรับปรุงเพิ่มมาเช่นกัน:
Branch Prediction: fewer bubbles, more accuracy, and throughput
- Zero-bubble conditional branches
- L2-sized (16K) L1 BTB and larger TAGE
- Larger return addresses stack (52 entry)
- 2 taken predictions/cycle
Memory management:
- Aggressive fetch hides L2 & table walk latencies
- 4x the L2 ITLB (2048 entry)
Icache latency and bandwidth
- 64B/cycle fetch
- 2 instruction fetch streams

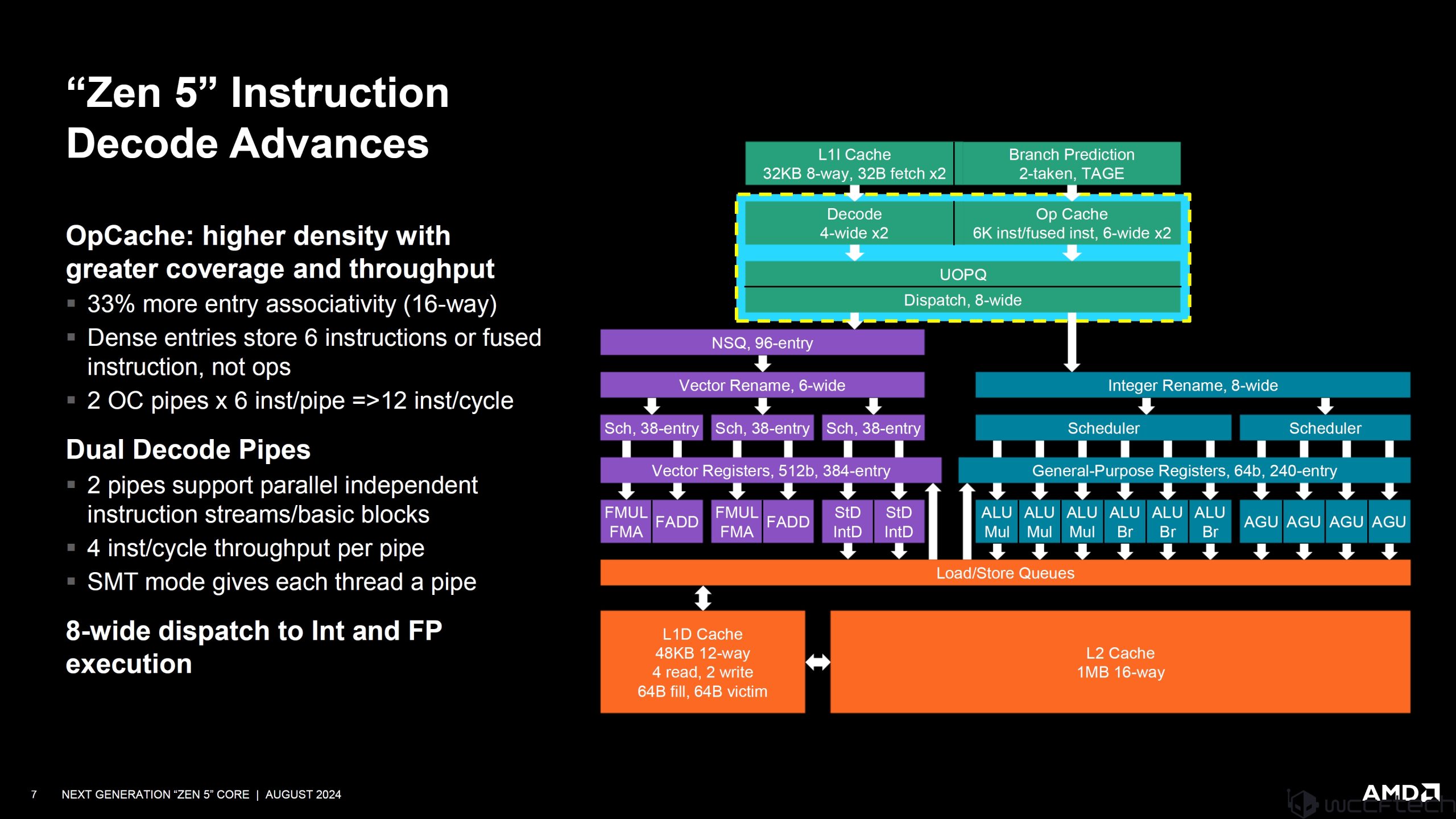
ต่อได้ส่วนภาคการถอดรหัส Decode Advances:
Opcache: higher density with greater coverage and throughput
- 33% more entry associativity (16-way)
- Dense entries store 6 instructions or fused instructions, not ops
- 2 OC pipes x 6 inst/pipe -> 12 inst/cycle
Dual Decode Pipes
- 2 pipes support parallel independent instruction streams/basic blocks
- 4 inst/cycle throughput per pipe
- SMT mode gives each thread a pipe
8-wide dispatch to Int and FP execution

ระบบการทำงาน Execution Advances:
8-wide dispatch, rename, retire
Integer scheduler advances
- Unified with age matrix
- More symmetry, simplifying pick
6 ALU with 3 multipliers, 3 branch units
4 AGU feed a wider LS with 4 memory addresses per cycle
Execution window growth
- Scheduler growth
- 240-entry physical register file
- ROB/retire queue 448/224 1T/2T entries

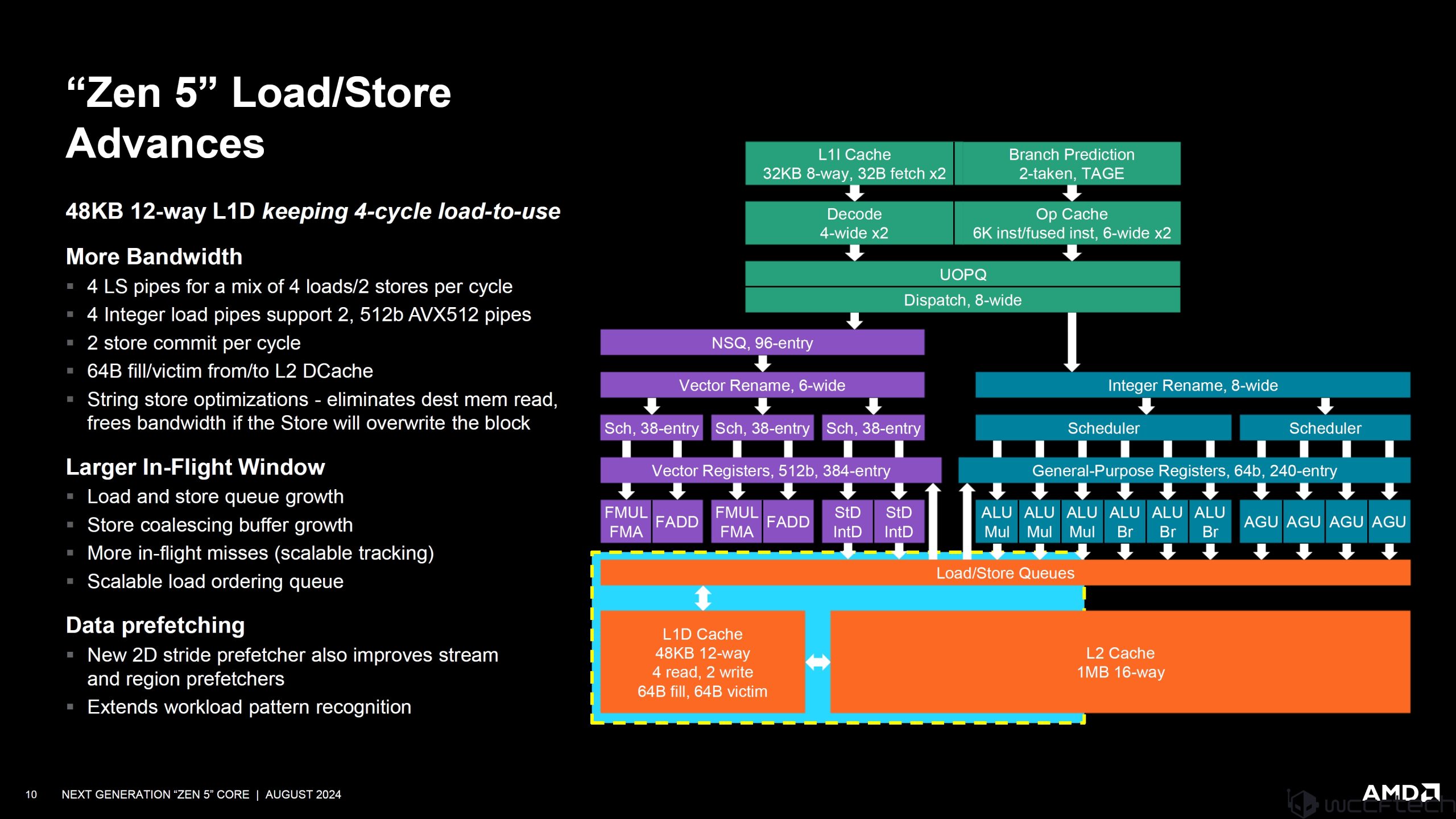
ปิดท้าย Load และ Store advances:
48KB 12-way L1D keeping 4-cycle load-to-use
More Bandwidth
- 4 LS pipes for a mix of 4 loads/2 stores per cycle
- 4 Integer load pipes support 2, 512b AVX512 pipes
- 2 store commit per cycle
- 64B fill/victim from/to L2 DCache
- String Store optimizations – eliminates dest mem read, frees bandwidth if the Store will overwrite the block
Larger In-Flight Window
- Load and Store queue growth
- Store coalescing buffer growth
- More in-flight misses (scalable tracking)
- Scalable load ordering queue
Data prefetching
- New 2D stride prefetcher also improves stream and region prefetchers
- Extends workload pattern recognition

ด้านการเชื่อมต่อ L2 ก็เพิ่ม 2 เท่า มาเป็น 16 ทาง และมีไซเคิลน้อยลง 3.5 รองรับ L3 มากขึ้น 32/16 MB (Zen 5 / Zen 5C) มีขนาด 4MB ต่อคอร์ใน Zen 5 และ 2 MB ต่อคอร์ใน Zen 5C
ด้านการจัดการพลังงานนั้นมีการปรับปรุงใหม่ตั้งแต่พื้นฐาน เพิ่มการทำงานที่ดีมากขึ้นและรองรับ 2T (major pref/watt benefits) ต่อด้วยฟีเจอร์ลดระยะเวลา power state entry/exit ลดพลังงานจากการทำงานที่ไร้ประโยชน์ และยังปรับปรุงการทำงานโดยกำจัดเส้นทางที่แน่นหน้าของ บัส, แคช และ inter-core ผ่านการปรับแต่ง string operations optimizations และ prefetcher effectiveness และ efficiencies
บอกเลยว่ารอบนี้ AMD มาแบบแน่นมาก ประสิทธิภาพเชื่อว่าน่าจะจัดหนักจัดเต็มกว่าเดิมแบบรู้สึกกันได้แน่นอน ส่วนตัวรีวิวเดี๋ยวมีออกมาดูกันเรื่อย ๆ ไม่มีพลาดอยู่แล้ว รอติดตามกันต่อเนื่องเอาไว้เลย


ที่มา ibit.ly/InzUj